What I Learned About spotify/luigi
Dec 17, 2015
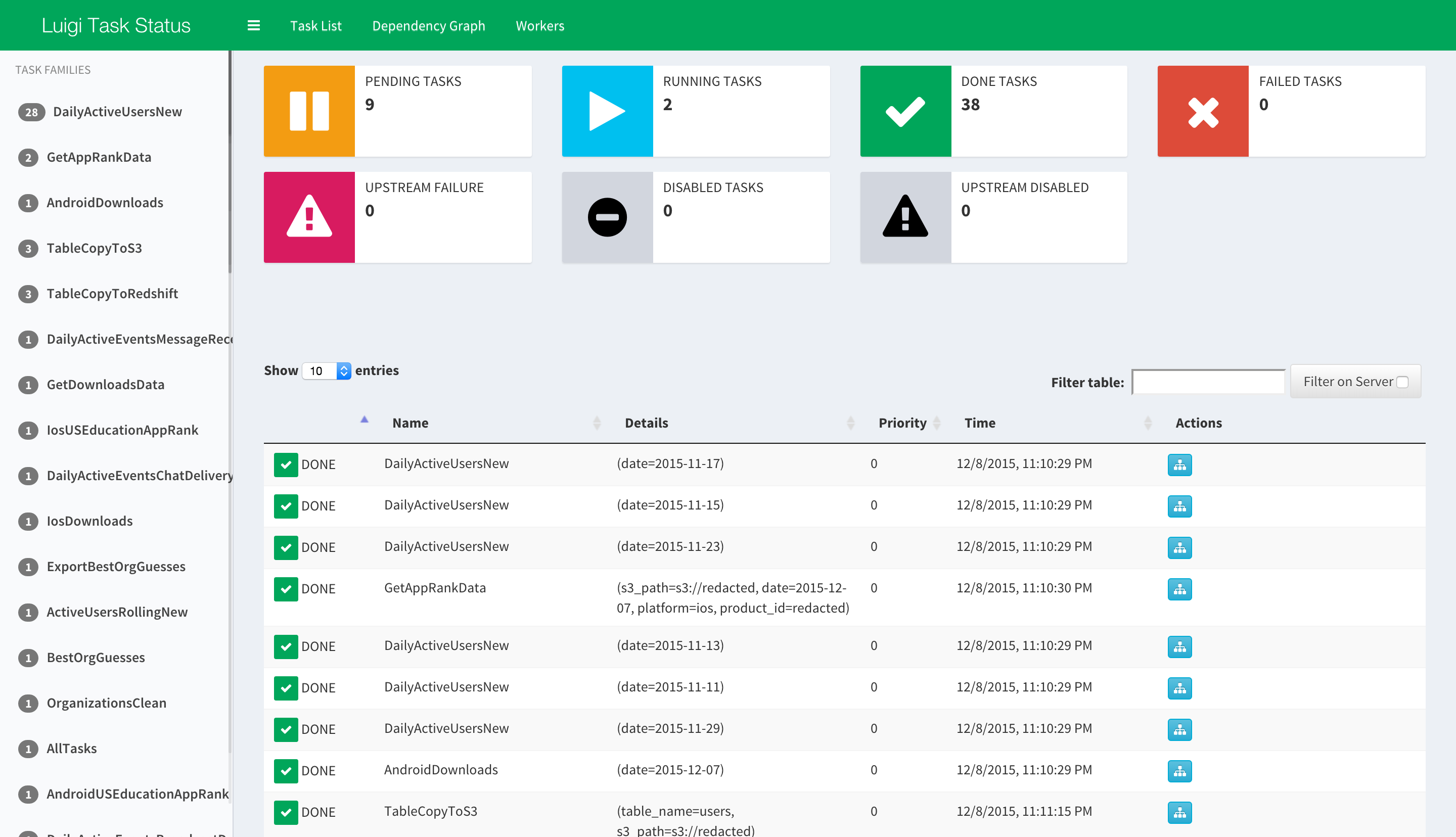
One task I worked on for the last month at my current internship was rewriting the ETL(Extract, Transform, Load) service to use spotify/luigi. It was my biggest project, and there were many interesting challenges I encountered along the way. I will share some of them today.
A little introduction first. Our previous ETL service was written in house. It moved very large amounts of data around our Redshift clusters, S3, and our Postgres database. While everything worked, it was starting to show much of its technical debt. It was difficult to extend upon, there was very little documentation, and the code base was not the easiest to understand. It was decided that a more simple and extensible framework was needed. We went the open-source route in search of a framework, and I eventually chose luigi after discussions with my mentor. The main reasons we chose luigi were its ease of extensibility, clean documentation, and large community support. With the framework decided upon, I set out to start migrating.
Reading from Postgres
The very first issue I faced was that luigi does not provide a Task base class that reads from RDBMS. Many of our tasks depends on data imported from Postgres into Redshift, so reading from Postgres was vital. This was solved easily. I created a base class that uses psycopg2 to dump a table from the production Postgres database to S3. This facilitated other tasks needing the data.
class TableCopyToS3(luigi.Task):
"""Dump a table from postgresql to S3."""
table_name = luigi.Parameter()
s3_path = luigi.Parameter()
def output(self):
return luigi.s3.S3Target(self.s3_path)
def run(self):
postgres_url = os.environ['POSTGRES_URL']
url_parts = urlparse.urlparse(postgres_url)
conn = psycopg2.connect(
host=url_parts.hostname,
port=url_parts.port,
user=url_parts.username,
password=url_parts.password,
dbname=url_parts.path[1:])
with self.output().open('w') as s3_file:
conn.cursor().copy_to(s3_file, self.table_name)
conn.close()
Using with containers
Containers are very popular where I intern. Every application is deployed using a custom PaaS framework built on AWS ECS. This made it convenient to scale applications by spinning up more containers, but containers introduced two problems. You cannot use luigi.LocalTarget to pass data from one task to another, and cron will not work properly.
You can no longer use luigi.LocalTarget because each container has its own filesystem. This I solved by only using luigi.S3Target. Using S3 to store files also comes with the added benefit of backup. This is not formally documented anywhere, but I needed to add the following lines to my luigi.cfg for S3 to work. I was only able to figure this out after reading through the source code.
[s3]
aws_access_key_id: AWS_ACCESS_KEY_ID
aws_secret_access_key: AWS_SECRET_ACCESS_KEY
cron does not work because containers should only run one process. There was the option of using an image like phusion/baseimage that supports cron and runs more than one process. This route was decided against because our PaaS framework monitors the process that each container is started with, and it will restart the container if the process behaves strangely. In a multi-process container, we only have visibility on one process. cron or any other process can break silently, and we will have no idea it broke unless someone decided to read the logs.
The approach we use is a long running task that the container runs. This a modified version of the python script:
import datetime
import time
import traceback
import luigi
import luigi.interface
import all_tasks
@luigi.Task.event_handler(luigi.Event.PROCESSING_TIME)
def on_success(task, exec_time):
# Report to metric tracker
@luigi.Task.event_handler(luigi.Event.FAILURE)
def on_failure(task, exception):
# Alert to bug tracker
def run():
cmd_args = [
'--date', str(datetime.date.today() - datetime.timedelta(days=1))
]
luigi.interface._run(cmdline_args=cmd_args, main_task_cls=all_tasks.AllTasks)
THIRTY_MINUTES = 30*60
while True:
try:
run()
except Exception as ex:
# Alert bug tracker
raise
print('Worker sleeping for {}'.format(THIRTY_MINUTES))
time.sleep(THIRTY_MINUTES)
AllTasks is a luigi.WrapperTask that wraps all our daily tasks. We have a container running luigid in the foreground, and multiple worker containers running this script. The benefits with the setup is that we will catch errors if the subprocess returns an error, new workers will start working on tasks as soon as they are launched instead of waiting for the next time cron triggers the script, and luigi handles task de-duplication for us when we run multiple workers with this script. There are also luigi callbacks that would report errors and metrics to other services baked in.
Multiple subtasks
I have one module called redshift that implements many useful tasks for manipulating our Redshift cluster. Within redshift, there are CreateTable, DeleteTable, UnloadTable, CopyIntoTableFromS3, InsertIntoTable, and etc tasks. By themselves, these tasks are useful, but they can also be combined.
For example, I have a task named CreateTableFromSelectQueryTask. This task takes in parameters table_name, select_query, and columns to create a table. It does the following in order: delete table, create table, and inserts the select query into the new table. The DRY way of doing this is reusing the DeleteTable, CreateTable, and InsertIntoTable tasks, but how do you chain them together? You cannot make them linear using each task’s requires() because these tasks are independent. What I did was make CreateTableFromSelectQueryTask as a wrapper task that calls the three aforementioned tasks.
There are three ways to call multiple upstream tasks from a downstream task. Returning an array of tasks from requires(), using yield, or directly calling run() on tasks. In code they are:
MultipleTasksA(luigi.Task):
...
def requires(self):
return [FirstTask(), SecondTask(), ThirdTask()]
MultipleTasksB(luigi.Task):
...
def run(self):
yield FirstTask()
yield SecondTask()
yield ThirdTask()
MultipleTasksC(luigi.Task):
...
def run(self):
FirstTask().run()
SecondTask().run()
ThirdTask().run()
There are benefits and drawbacks to each. Returning an array of tasks in requires() is the most conventional, it works with the luigid visualizer, and out of all three ways, the only one that will run the dependencies in parallel. yield is the probably the ‘proper’ way to do it since a wrapper task is supposed to delegate logic to the individual tasks. yield is also what’s in the documentation for a luigi.WrapperTask. run() is beneficial when you want the wrapping task to be atomic. When you call ‘run()’ on a task, you know that the task will be run. So if the wrapper task fails, everything will be re-run. The previous two methods will not re-run any wrapped tasks that are already complete. But this means that using the run() method does not give you the benefit of de-duplication that the others will.
Everything boils down to the use case. If the wrapping task does not need atomicity and is parallelizable, then use requires(). If the wrapping task needs to be serial, but does not need to be atomic, then use yield. And if the wrapping task needs to be atomic, then use run().
Wrap Up
Hope this was of interest. There were many other less significant challenges that I decided not to include like custom parameter types, staging vs production configuration, and specific Redshift and S3 related issues. However, feel free to send me an email about them. I would love to discuss them. I just hope I will still remember them.
Oh, and here’s a decently sized dependency graph.
